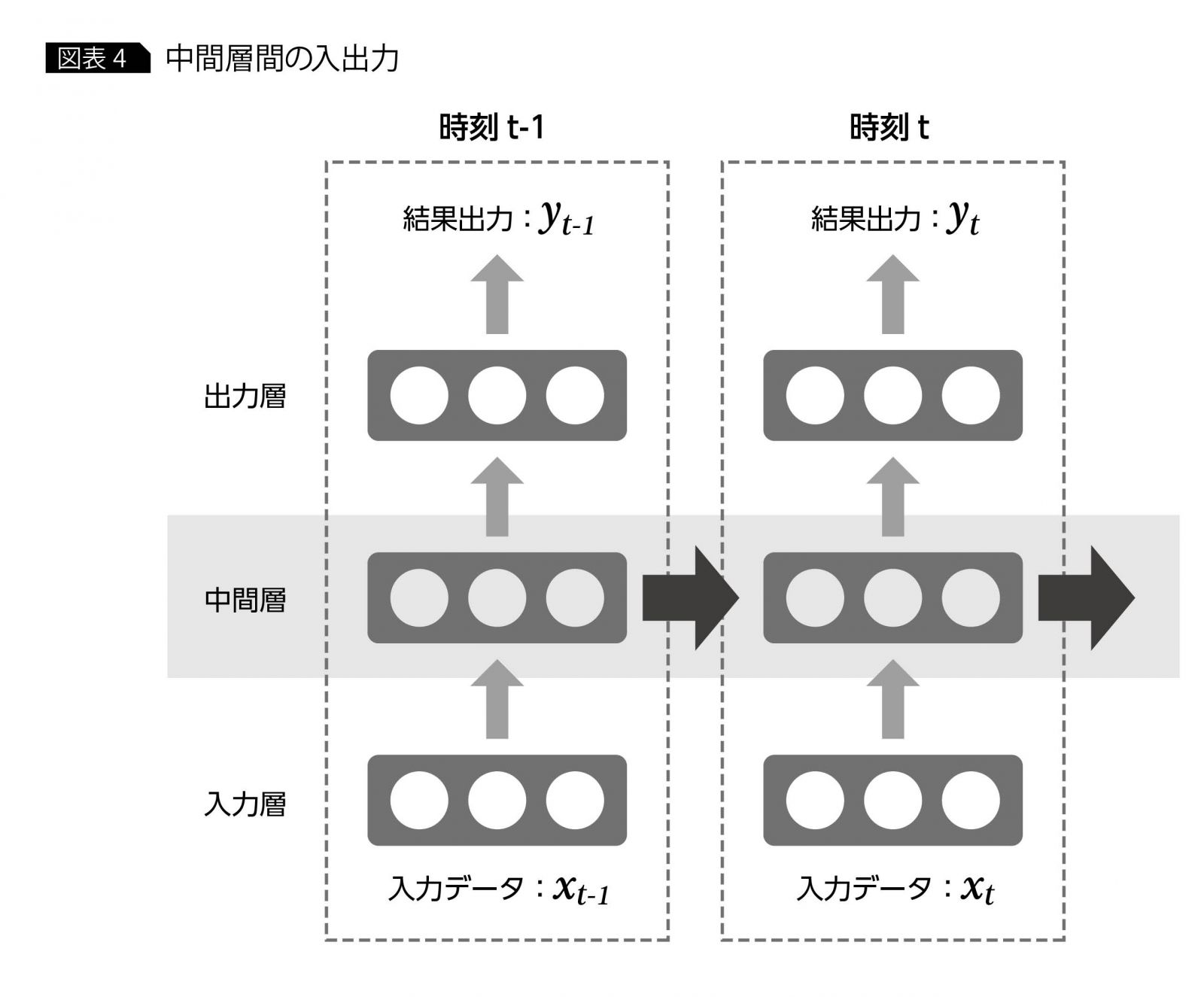
RNNLast updated Dec 16, 2022 Edit Sourcehttps://www.imagazine.co.jp/再帰型ニューラルネットワークの%E3%80%8C基礎の基礎%E3%80%8D/ニューラルネットワークが二つの目的を持って最適化される感じかな出力層は、普通に結果の損失関数を小さくするように訓練されていく中間層は、上手く次の時刻に渡せるデータを生み出せる様に訓練されていく感じ?